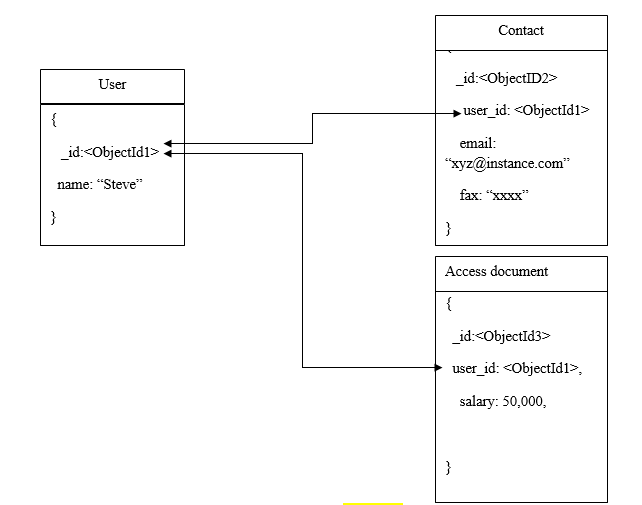
Due to the IoT devices and sensors being everywhere and gathering voluminous amounts of data, one of the most challenging issues is to assess the continuously growing data sets, particularly in real-time. For IoT systems, it is necessary to be capable enough to respond timely with the ever-changing trends so you can deliver real-time BI (business intelligence) that can have a major role in the IoT solutions’ success. If you are using an event-driven architecture for your internet of things ecosystem then the following patterns can hugely benefit you.
Complex Event Processing
Complex event processing tackles the issue of repeated incoming pattern events. Generally, the matching culminates into complicated events that are itself created from the input events.
In conventional DBMS, typically a query is run on stored data; on the other hand, complex event processing runs data on a stored query.
You can eliminate any irrelevant query data. CEP is useful as they are applicable to infinite data streams. Moreover, the processing of input data is quick. When the IoT ecosystem checks all the matching sequence events, results are released. As a result, it helps with the analytics capabilities of the complex event processing.
Put simply, event processing is used for the identification of events (like threats or opportunities) and generates a response for them prior to its occurrence or in its aftermath. Bear in mind that event-driven architecture and complex event processing are closely interlinked.
Event Processing
For creating IoT-scalable applications, one of the more popular distributed architecture patterns is the event-driven architecture. The pattern comprises of single-purpose and highly decoupled components of event processing which process and receives events with an asynchronous format.
One specific area where an event-driven architecture can come in handy is those complex engineered system with a loosely coupled structure. There is no need to specify a formal or bounded infrastructure to categorize components. Instead, you can introduce autonomy for the components that are open to both decoupling and coupling with various networks while responding to a wide range of events. Hence, it is possible to reuse IoT components with separate networks.
Mediator and broker are the two primary topologies of the event-driven architectures. The mediator topology is often required when you have to orchestrate several steps with a central mediator for an event. On the other, broker topology can be useful when you do not want to work with a central mediator for chaining events together.
Mediator Topology
Events that have a wide range of steps and need to process the event with orchestration can use the mediator topology.
The mediator topology offers event processors, event channels, event mediator, and event queues. The flow of the events begins when an event queue receives an event from a client, which is usually required for the event’s transportation to the event mediator. After getting the initial event, the event mediator performs the orchestration of the event; to do this, it sends more asynchronous events towards the event channels for executing all the process steps. The event channels are listened by the event processors who are given the event by the event mediator. Afterward, certain business logic is executed for processing the event.
Broker Topology
The broker topology is not the same as the mediator topology because of the lack of a central event mediator. Instead, a message broker is used to distribute the message flow between the components of an event processor with a chain-like approach. This topology is primarily used when there is no central event orchestration and the event processing flow is relatively straight-forward and simple.
Broker topology is composed of two components: an event processor and broker component. The broker component can be federated and centralized; all the event flow’s channels are stored by the broker. These channels can be message topics, message queues, or both.
Event Sourcing
The pattern is used to specify the methodology for managing data operations which are driven by a sequence of events—an append-only store saves all of them. An event-based series is sent by the application code which contains details of all the actions that have been performed on the event store’s data.
The concept around event sourcing revolves around the idea that when a system’s state is modified, the change of state can be referred to as an event. This means that the system can be reconstructed in the future if the events are reprocessed. The primary truth source is the event store where the system state entirely depends on it. A version-control system is one of the examples of this idea.
Events are raised by the event source and operations are performed by tasks in reply to those events. This tasks’ decoupling allows for achieving greater extensibility and flexibility. The event data or type of event, such details are known by the task, although they are unaware of the actual operation that invoked the event. Furthermore, every event can be managed by several tasks. This helps with integrating other systems and services that look for any latest event from the event store.
The events of event sourcing are typically on a low level; it is possible that you might need to create specific integration events.
An append-only operation is used to store events; they are asynchronous and immutable. In the background, tasks run to manage the events. Additionally, if the transactions’ processing suffers from lack of contention then scalability and performance can be significantly improved for IoT applications, particularly while working with the user interface and presentation level.
However, there are certain issues with the event source as well. For instance, there are no existing solutions or standard strategies like SQL queries to read the events for procuring information. To assess the current entity’s state, all events can be replayed which link with it against the original entity’s state. The process of replaying events has its own pitfalls, such as the outside systems’ interactions on which the results rely.