
Before reading about event-based architecture, you will need to understand what an event is. An event can be termed as any ‘change’ that occurs between two states. For example, a module in application sends a message to another component. This message can be the event that will trigger a change in the processing of the system. Event-based architectures are favored because they help software development of asynchronous and scalable applications.
What Is Event-Based Architecture?
Event-based architecture is a type of software architectural design in which the application component receives the notification of an event. As a result, a response is generated. In comparison to other paradigms, event-based architecture is considered loosely coupled. EDA can be considered as an approach for coding software solutions where the heart of the architecture lies in ‘events’ which process the communication between different components.
How Does Event-Driven Architecture Work?
The architecture has several components that help to speed up the development process of an application.
Queue
In an event-based architecture, the requests accumulate into queues called event queues. From these queues, the events are then sent to the services where they are processed.
The events in this architecture are collected in central event queues. For example, check the following diagram.

S here denotes the service. The queue will provide an event for each service accordingly.
Log
The event log exists on the hard disk. It consists of the messages that were written for the event queue. An event queue is useful because in case of an unexpected system shutdown or crash, rebuilding can be eased through the contents of the event log. The following diagram will help to explain the event log’s place in the architecture.

The event log can also be utilized for any future back up. This back up can take the entire state of the system which can be critical in testing. The comparison between the performance of both the old and newer releases of an application can be analyzed through this backup.
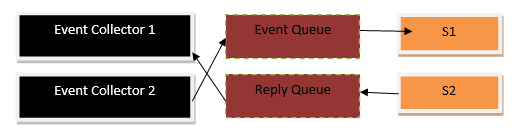
Event Collector
Okay so far we have talked about the collection of the events in the event queue but how exactly are the events received? Well, the answer lies within the term ‘event collector’. These collectors get requests from protocols like HTTP and forward them to the event queue. Further understanding can be gained through the following diagram.

Reply Queue
Not all the events can be categorized as same. Sometimes, an event does not require a response. For example, a user has entered some data in a feedback form. In this case, the system does not require sending a response. However, some events require the system formulating a response for a request. The request here will be called as an ‘event’ in our architecture. For this response, a reply queue is needed which will utilize the event queue. The collectors that forward the events can also provide the response back. However, it must be noted that the event log does not record the contents of the reply queues. The following diagram can explain the reply queue.
Read vs. Write
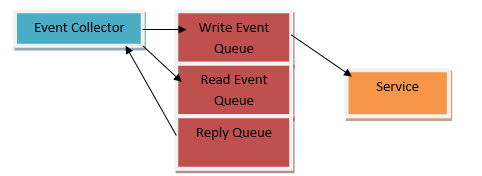
When all the requests from the collectors act as an event to trigger a function, then all of them are added in the event queue. In the case, this queue is linked to the event log. All the requests are persisted which slows down the system. If some of the non-important requests can be eliminated then the event queue’s processing can be increased considerably.
The core concept behind this persisting of events is the rebuilding of the former states of a system. This means, events that actually modify the state of the system, need to be persisted to the event log. This can be done through the classification of events into write and read events. A write event is one in which the states of the system are modified while a read event does not modify any state. As a result, the application can now only persist during the write events which in turn will provide a much-needed boost to the management and processing of the event queue.
Ratios between both read and write events can be drawn to further gain an understanding of the difference. For instance, our system has 10 events. Out of the 10, only 2 events are actually changing the state of the system. Without classification, we can find all of them to be slowing the speed of the event queue through persistent to the log. However, by dividing them between read and write events, only 2 of our events require to be persisted. Subsequently, the other 8 read events cannot risk the speed of the queue.
Now a question arises. How to distinguish between these events? Events should be distinguished through the collectors. If a collector does not separate them, then the event queue will be unable to make a decision of its own.
Another approach is to divide an event queue. One event queue will be responsible for dealing solely with the read events while the second one can look after the write events. This saves the resources as no other component in the system has to decide on the persistence of the events. The following example shows the idea behind this approach. Some may feel that it may make the system more complex but in reality, it is reducing the workload of the application.
Final Thoughts
The main benefit of event-based architectures is seen while working with scalable enterprise applications. Event-based architecture also particularly assists in the testing phase and can generate productivity in test driven approaches which means that each core component of an application can be designed and developed separately. Additionally, with low to no coupling, the architecture stands as an excellent choice for the removal of complexity in applications.

Pingback: Evolution of Event-Driven Architecture – IT Tech Book
I enjoy studying and I believe this website got some genuinely useful stuff on it! .