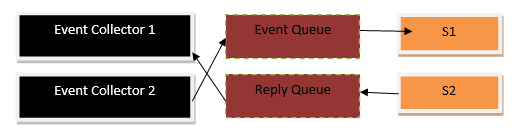
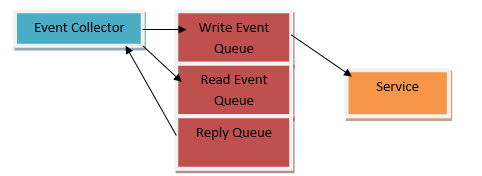
A message-driven architecture can have the following components.
- Producer – The one that generates a message and then forwards it ahead.
- Consumer – The one for whom the message was intended; who will then read it and process accordingly.
- Queue – A communication model that saves the messages so they can be sent ahead to other services for processing.
- Exchange – It is a queue aggregator. This means that it can apply abstraction on the queues and manage the messages so they can be sent to the right queues.
- Message – It consists of the headers which contain metadata as well as a body. The body entails the actual contents of the message.
A message-driven architecture also needs a message broker. This message broker decides who should send the message or who should receive it.
Surely, the benefits of the microservices outweigh those of monolithic applications but the paradigm shift means that you will have to look into the communication protocols and processes between various components of your application. By using the same mechanisms of monolithic systems in a microservices application, it may impact the performance of the system and slow it down, particularly if you are coding distributed applications.
To counter such problems, the isolation of the microservices architecture can be helpful. For this purpose, asynchronous communication can be utilized to link microservices. This can be done through the grouping of calls. The services in a microservices application are often requires interaction through protocols like HTTP, TCP etc.
The general opinion of the developers regarding the microservices architecture is to inject decoupling in applications while maintaining the cohesiveness of the system. A true microservices applications is one in which each service has its own data model and business logic.
A protocol can be either asynchronous or synchronous. In the synchronous protocol, a client can forward a request. The system will then listen for a response. The entire process is independent with client code execution. An example of such messaging is the HTTP protocol. In asynchronous protocols, the sender will not listen or wait for a response.
Types of Message Brokers
There are many message brokers that are used for message-driven architectures. Some of these are the following.
RabbitMQ
RabibtMQ is perhaps the most popular message broker out there. It is open-sourced and uses the Advanced Message Queuing Protocol (AMQP) with cross-platform functionality. Whether you are a Java developer or a C# one, all of your microservices can be used to communicate the message with different microservices.
Azure Event Hub
This one is a PaaS (Platform as a Service) related solution that is offered by Microsoft Azure. It does not need any management and can be easily consumed by a service. It also uses AMQP. It basically has an Azure Event Hub that works with partitions and communicates with consumers and receivers.
Apache Kafka
Kafka is the brainchild of Linkedin and was made open-source in 2011. It is not dissimilar to Azure’s solution and has the capability to manage millions of messages. However, the difference stems from the fact that unlike the Event Hub, it works with IaaS (Infrastructure as a Service). Though, newer solutions are also integrating Kafka with PaaS.
There are two types of asynchronous messaging communications for message-driven architectures.
Single Receiver
Single receiver message-driven communication is particularly helpful when dealing with asynchronous process while working with different microservices. A single receiver is one in which a message is sent only once by its consumer. After forwarded, it also will be processed only once. However, it must be noted that at times a consumer may send the message more than once. For example, there is an application crash; the application will try to repeat the message. In the case of an event like an Internet connectivity failure, the consumer can send a message multiple times. However, it must be noted that it should not be combined with the HTTP communication that is synchronous. Message-driven commands are especially useful when developers scale an application.
Multiple Receivers
To get your hands on a more adaptable technique, multiple receivers message-driven communication can be proficient. This communication utilizes the subscribe/publish strategy. This refers to an approach where a sender’s message can be broadcasted to multiple microservices in the application. The one who sends a message is called the publisher while the one who receives it is called the subscriber. Additionally, further subscribers can be added to the mix without any complex modification.
Asynchronous Event-Driven
In the case of asynchronous event-driven communication, a microservice will have to generate an event for integration. Afterward, another service is fed with the information. Other microservices engage in the subscription of events so messages are received in an asynchronous manner. Subsequently, the receivers will now have to upgrade their entities that entail information regarding the domains so further integrations events can be published.
However, here the publish-and-subscribe strategy requires tinkering with event bus. The event bus can be coded in such a way that it occurs as a means of the interface while dealing with API (Application Programming Interface). To be more flexible with the event bus, other options are available through processes like a messaging queue where asynchronous communication and the publish-and-subscribe strategy are fully supported.
However, it must be noted that all the message brokers have different levels of abstraction. For example, if we are talking about RabbitMQ, then it has a lower level abstraction if we compare it with solutions like MassTransit or Brighter. Brighter and others use RabbitMQ for abstraction. So, how to choose a message broker? Well, it depends on your application type as well as the scalability needs. For simple applications, a combination of RabbitMQ and Docker can prove to be enough.
Though, if you are developing large applications then Microsoft’s Azure Service Bus is a powerful option. In the case of desiring abstraction on a greater level, Brighter and MassTransit are the good options. If you are thinking about developing your own solution then it is not a good idea since it is time-consuming and the cost is too high.