Have you finally taken a leap of faith and resolved to adopt the microservices architecture? Hopefully, it is for the best. The other out-dated solution architecture might have been compromising the performance, security, and customer satisfaction of your applications, website or mobile app.
However, as you will delve deeper in the microservices world, you will face certain hiccups. Thankfully, a number of design patterns and best practices have been introduced in the software community that can help you to tackle these challenges and move forward with your application.
API Gateway
While using the micro-services architecture, often the client-side has to face a certain issue. The problem stems from the client’s inability to gain access to different services. Through applying the API gateway pattern, client-side is provided with a single access point.
This point acts as a center from which it can interact with other services of the application. Sometimes, the API will send a request from the client to its suitable receiver while other times, more than a single service will receive the request. As a result, the client-side does not need to fall into the complexities about how different microservices have been split up by the application.
Service Registry
Often microservices in an application struggle to locate the free instances of the services. In this case, the service registry can be helpful. Service registry can be basically considered as a DB for all of your services.
It holds the instances of the services which are registered and de-registered on each startup and shutdown. Hence, clients can search for any available or free instance through the service registry. However, there are few problems that are related to the pattern.
One of them is that it needs constant configuration and management. In case a service registry falters, crucial data can be lost. Hence, it has to be ensured that the service registry is always available for use by the application.
Circuit Breaker
In a microservices application, services often have to communicate and execute tasks together. A service can receive a request for which it has to call another service for action. However, the summoned service can sometimes be unavailable due to an issue. In such a predicament, valuable resources can be wasted and the actual service that was called will not be able to process other incoming requests. As a result, one service’s failure incurs a significant loss to the entire application’s resources.
In such events, ‘circuit breaker’ is the need of the hour. It is a remote service that listens to the communication between two services. If a service fails to respond after a certain limit, then the circuit breaker will trip. The summoned service cannot communicate any further during the timeout interval. After the interval, few requests can be accepted by the circuit breaker to see if the service has regained its working. In case the service is working, the communication will be restored. However, a timeout interval will follow if the called service is still unavailable.
DB per Service
Let’s suppose you are working with an e-commerce application. For the order of products, you have an ‘Order’ service while for payment, there is a ‘payment’ service. Since the majority of the services require data to be stored, how will you manage your data storage of services? Since it is a microservices application, you cannot use a single DB. Instead, you can link each microservices’ API with its own DB.
As a result, each service will be able to keep its data confidential. You can also try to use separate tables, schemas and DB servers for your services. With every service having a dedicated DB, one of the primary requirements for microservices architecture, loose coupling, is achieved. Additionally, each service will be able to use a DB according to its needs.
Health Check API
Often, a service instance is running fine but it is unable to process requests. This can happen if the DB connections are not available. For this scenario, a monitoring mechanism is required that can serve as a warning tool. Hence, in order to alert about a running service that is facing difficulty in processing requests, we can use health check API. As the name suggests, it is used to examine and alert about the health of a microservice. The API will examine things like application-specific logic, disk space, connection status etc. However, it must be noted that a service instance can still falter in the middle of a health check and thus the pattern should not be considered to deliver 100% success.
Messaging
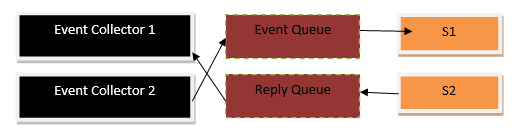
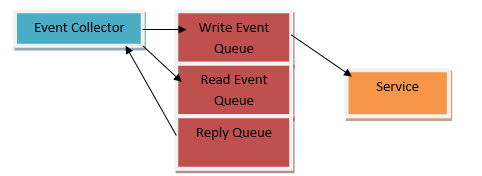
For handling and processing the requests from the clients as well as working together with other microservices, a standard communication mechanism is required that can enhance the performance of the application through effective communication. For this purpose, the asynchronous message can be the solution to your problems. It helps in inter-service communication through which microservices are able to pass all types of messages to each other. Kafka and RabbitMQ are one of the most popular messaging tools available. Due to the message broker mechanism, requests are handled better and do not get lost. However, the message broker has to be available 24/7 while the client will also need to know the message broker’s address.
Log Aggregation
While dealing with a large application that is built on microservices architecture, you will have to deal with a number of instances spawning from each service. There would be a continuous stream of requests that have to be handled by all the instances. These instances produce information about their workings to a log file.
The log file will entail debug, warnings, errors and other information. Hence, in order to increase the understanding of an application’s complete behavior, a logging service can be used that is based on the centralized model. The service will help to accumulate the log data from all the instances of services. As a result, IT professionals can find and understand these logs and apply configuration for alerts so any important message can be displayed on a priority basis.